

El mejor aliado de la IA... son tus propios datos.
Cómo la inteligencia artificial generativa nos puede ayudar a crear barreras de entrada construidas con nuestros datos.

Esta semana he participado en un workshop con el comité de dirección de una empresa de software con una base enorme de clientes y una penetración de mercado del 80%. Reconozco haber sentido la presión hablando con directivos de una industria muy familiarizada con la IA. Aún con diferentes niveles de conocimiento, todos eran conscientes de la oportunidad que se abre ante ellos. Por un lado, como en toda industria, pueden aspirar a una mejora en la productividad personal y en los procesos asociados a diferentes funciones corporativas. Por otro lado, serán capaces de desarrollar software mucho más ágilmente gracias a la capacidad de los LLMs de crear y corregir código fuente (una lectura interesante al respecto en los enlaces finales).
Pero lo que más resonó en la mesa, fue la gran oportunidad en la diferenciación de producto si ponen sus datos a trabajar. Datos que de los que pueden disponer ya, o datos que podrían llegar a obtener con ingenio y creatividad, gracias a un acceso privilegiado a sus clientes y sus instalaciones.

Las herramientas de IA generativa facilitan el acceso a tecnologías avanzadas, permitiendo que incluso pequeñas empresas puedan beneficiarse de sus capacidades. Pero herramientas que cuestan solo unos pocos euros al mes en sus versiones de pago no pueden, por sí solas, representar una ventaja competitiva sostenible. Estas al alcance de cualquier organización o individuo, lo que iguala el terreno de juego y limita la exclusividad de su uso. Tenemos que entender cómo combinar estas herramientas con nuestros propios datos para realmente marcar la diferencia frente a los competidores.
Entramos en período de desconexión veraniega y con un año ya de Rebel Intel a las espaldas, tiene sentido mirar atrás y recuperar alguno de los artículos pasados que mejor han envejecido. En la edición de hoy, recupero y combino los dos más relevantes publicados alrededor de la IA y la gestión de los datos.
Nuestra actitud frente a los datos.
Siempre doy alguna conferencia o curso sobre data-driven marketing me parece ingenioso utilizar este gráfico de The Economist Intelligence Unit:

Sólo un 10% admite sin rechistar los datos que contradicen su intuición. Me veo reflejado. Es normal poner en duda el dato, la fuente del dato y a la madre que trajo al mundo a ese dato en concreto que va en contra de nuestro “gut feeling”. Somos humanos. A nuestros genes no les interesaba el análisis estadístico sino la supervivencia en un mundo cruel. Somos un jinete intentando controlar a un elefante. Por eso nos dejamos arrastrar por la intuición y el análisis superficial. Le damos demasiada importancia a nuestro punto de vista o nuestras experiencias personales. Creemos que nuestra realidad es reflejo de toda la realidad y nos cuesta entender la complejidad del mundo. Así que al final terminamos cuestionando la fiabilidad de los datos y preferimos seguir nuestro instinto.
Mi amigo (y socio en Foxize) Fernando de la Rosa se ha embarcado en una cruzada para conseguir que los directivos españoles tomen mejores decisiones usando los datos. Su nuevo libro pretende que tomemos mejores decisiones aprendiendo a usar los datos. Hace tiempo escribía sobre los diez errores de las decisiones con datos. Selecciono uno:
#5 Error – No revisar nuestras emociones.
Un comercial no es objetivo al explicar los resultados de ventas. El motivo es simple, ha estado vinculado con cada una de las ventas. El acumulado de las cifras de ventas, es fruto de su trabajo. El director financiero mira los números con una emoción diferente. Las emociones nos hacen tomar decisiones – acertadas o equivocadas. Seguro que el comercial defenderá los datos de una forma muy diferente que cualquiera en la sala.
En un extenso whitepaper que elaboramos en Good Rebels, Data Driven Marketing, explicábamos la importancia de construir una cultura y una estrategia empresarial basadas en la comprensión y el tratamiento inteligente de los datos. Y usábamos una evolución marcada por varias fases: desde un primer estado data blind -en el que no existe una estrategia de negocio en torno a los datos- hasta culminar con el análisis integral de los datos.
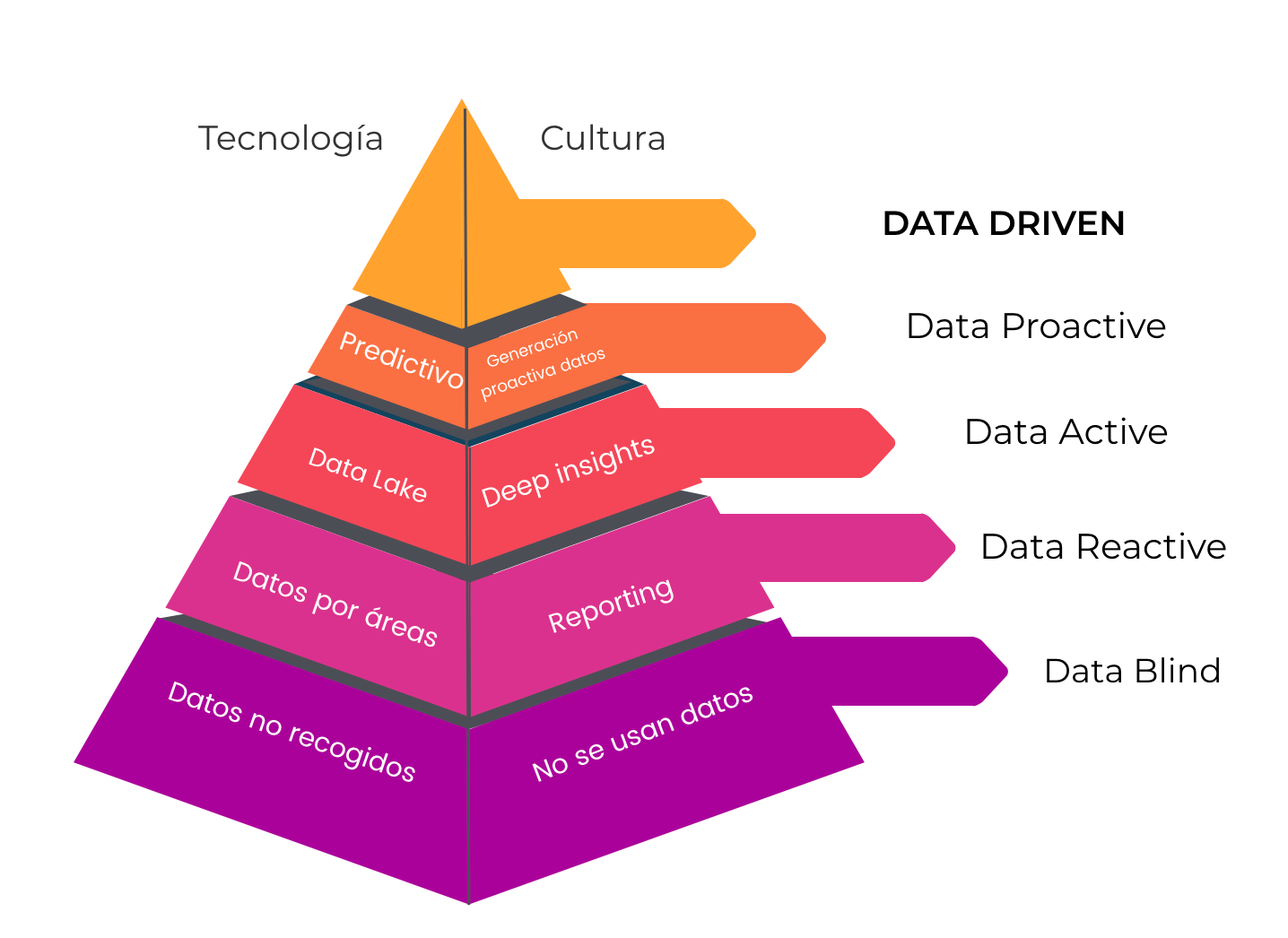
La cadena de valor del dato.
El peor enemigo de la gestión de datos en una organización, es la propia organización. Silos funcionales, fusiones y adquisiciones, enemistades personales o dejadez burocrática hacen que la captura y almacenamiento del dato generen dispersión y falta de visibilidad. Llevamos años colaborando con organizaciones para construir lo que se denominó Data Lakes, una forma de usar la tecnología para organizar y almacenar un descomunal volumen de datos que pueden recibirse en formatos diferentes (estructurados, no estructurados), desde fuentes diversas (internas, externas) con el fin de evitar cualquier transformación que pueda sesgar el análisis futuro. Recordamos con especial cariño nuestro proyecto con Aliseda. Hoy día esos lagos de datos se construyen sobre tecnologías al alcance de cualquier bolsillo.
La IA también ayuda a capturar y a limpiar datos. Y los LLMs pueden ser utilizados para añadir estructurar o limpiar datos semiestructurados. ¿Cuáles son los temas tratados en un documento? ¿Cuáles son las ciudades (o medicamentos o empresas de software) mencionadas en un informe? O generar textos alt para imágenes en la web con modelos IA que son capaces de describir una imagen.

Se lleva usando IA desde hace décadas para analizar datos. Un algoritmo tipo K means nos puede ayudar a hacer clusters de cliente por análisis RFM (recency, frequency and monetary) de una base de datos de transacciones comerciales. Las entidades financieras llevan años prediciendo el fraude con algoritmos si no inteligentes, sí muy espabilados. Pero demasiadas veces, aunque los datos se almacenen correctamente y estén accesibles, se quedan abandonados en un cajón cogiendo polvo, muertos de risa, criando malvas. Y aquí también puede ayudar la IA generativa.
¿Qué aporta la IA Generativa a la gestión de datos?
Muchas empresas manejan datos no estructurados en multitud de formatos: están en correos, vídeos, documentos de texto, emails, redes sociales… ¿Cuántas son las empresas que pueden decir que tienen ordenado y clasificado todo ese material? Es un trabajo complejo y pesado, especialmente si hablamos de sectores que trabajan con grandes cantidades de información personal.
Al mismo tiempo, cada vez más empresas están utilizando LLMs para obtener algún tipo de beneficio (mejorar la comprensión de sus clientes, automatizar la atención, afinar sus campañas, personalizar las interacciones, etc). Y se requiere esfuerzo para asegurarse de que los datos -propios- utilizados han pasado por las fases de arquitectura e ingeniería, y de ese modo ofrecen garantía de calidad y seguridad en el uso.
Y aquí aparece un buen giro de guión: la IA generativa, capaz de generar outputs gracias a su entrenamiento con enormes cantidades de datos no estructurados puede ayudarnos a organizar nuestros datos. Nos ayuda a limpiar los datos eliminando el ruido (corrigiendo anomalías), descartando datos corruptos o no válidos. O a enriquecer los datos con etiquetas de metadatos. Los metadatos son descripciones de los datos no estructurados, donde se especifica información como el origen, las relaciones entre datos, si hay o no derechos de propiedad, etc... Los metadatos garantizan que los algoritmos hacen un uso optimizado de los datos.
También nos puede ayudar a romper silos organizacionales: conectando bases de datos, encontrando datos duplicados, incompletos o no estandarizados, que la IA se encarga de ordenar y unificar. O anonimizar datos para garantizar la confidencialidad en entornos afectados por la privacidad. Encapsulando los datos que contienen información sensible o identificable, y conservando las propiedades estadísticas de los datos originales.
Y también puede generar datos: la IA puede crear sets de datos “sintéticos” que imitan las características y propiedades de los datos reales, cuando no disponemos de suficientes datos para entrenar modelos de IA o son difíciles de obtener.

Relacionándonos con los datos en lenguaje natural.
Otra de las grandes ventajas de la IA generativa, que no es exclusiva para la gestión de datos, pero que va a tener una gran relevancia, es que nos permite entablar conversaciones en lenguaje natural con los datos. Lo hemos experimentado con el lanzamiento el año pasado de Code Interpreter en ChatGPT Plus (y que se ha introducido en la funcionalidad para crear asistentes). Subimos un fichero excel y le pedimos a ChatGPT información sobre los datos del fichero. El sistema escribe y ejecuta código Python en un entorno de ejecución aislado, de forma iterativa para resolver problemas de análisis de datos, matemáticas y código más complejos.
La tecnología Natural Language to SQL (NL2SQL) permite a cualquier persona, sin conocimientos de programación SQL tradicional, consultar bases de datos y extraer información utilizando lenguaje natural. Cualquier profesional MCX o de otra actividad sin background técnico (un médico, un abogado, un profesor…) puede articular sus dudas y obtener una respuesta sin depender de un analista de datos.
El auge de las bases de datos vectoriales.
Las bases de datos vectoriales están cambiando la manera en que gestionamos y accedemos a grandes volúmenes de datos, tanto estructurados como no estructurados. Su gran ventaja es la capacidad de representar datos complejos en un formato eficiente. Al convertir los datos en vectores y ubicarlos en un espacio multidimensional, la IA generativa es capaz de capturar las relaciones semánticas, el contexto, y las similitudes entre distintos sets de datos, lo que permite búsquedas y análisis más sofisticados para extraer insights y correlaciones. Particularmente útil para trabajar con información compleja como imágenes, texto y sonido, que no se ajustan fácilmente a estructuras tabulares. Si quieres saber cómo funcionan con mayor detalle, este artículo en español me ha parecido bastante completo.
Junto con las bases vectoriales, la IA generativa nos acerca más a la promesa de una búsqueda semántica (y con lenguaje natural) para acceder a todo el conocimiento de una organización, por ejemplo. Buscando romper “silos funcionales”, accediendo a diferentes sistemas y como hemos explicado arriba, creando “metadatos” que ayuden en las búsquedas más complejas.
La IA generativa se convierte en un aliado clave para limpiar, estructurar y acceder a nuestros datos. Pero si descuidamos la gestión de los mismos, estas herramientas no nos ayudan en el día a día, pero no proporcionarán una ventaja diferencial y sostenible en el tiempo.
El próximo domingo, vuelvo a tu buzón.
Fernando.
Hace tres semanas, Fernando de la Rosa (al que menciono más arriba) y yo grabamos en directo una conversación alrededor de la Inteligencia Artificial. Lo hicimos respondiendo a preguntas enviadas por la comunidad de Foxize en los días previos al webinar. Sobrevolaron la sesión puntos de vista diversos desde múltiples ángulos e incógnitas difíciles de resolver. Puedes ver la sesión completa (60’) aquí:
Enlaces de interés para el profesional MCX.
Lecturas seleccionadas de la semana:
Nibble es una plataforma que promete mejores conversiones en tiendas online, gracias a un chatbot que negocia descuentos con los clientes. Presumen de tener un equipo de académicos expertos en negociación, pero leyendo un tuit que se coló en los chats internos de Good Rebels y comprobando el control que tiene sobre las respuestas (sin “alucinaciones”, potencialmente dañinas a la hora de negociar) me puse a tirar del hilo (¿es IA generativa, es IA simbólica?). En este post, su CTO explica cómo combinan bloques tradicionales predefinidos de respuesta por IA simbólica, con LLMs. Si de verdad te interesa cómo se está avanzando para superar las limitaciones de la IA generativa, este post es un must. NIBBLE

¿Son los modelos de lenguaje grandes (LLMs) siempre los mejores? Cada vez más, asistiremos a soluciones y arquitecturas que combinan diferentes modelos (grandes, medianos o pequeños) con aplicaciones específicas para garantizar el resultado y la eficiencia. Un buen artículo que he descubierto en el interesante blog sobre inteligencia artificial de IBM, después de que en la reunión del Foro IA de esta semana, David Carro nos apuntaba a la silenciosa estrategia que está siguiendo IBM: foco en B2B y enfoque “open source”. Entre otras cosas, han desarrollado un framework para entrenar LLMs con datos sintéticos y han creado InstructLab para permitir a la comunidad hacer contribuciones a modelos open source existentes. LLMs, INSTRUCT LAB
Sobre la llegada de los Small Language Models, OpenAI acaba de anunciar 4o-mini, un modelo pequeño que supera a la primera versión de GPT-4 y cuesta 30 veces menos que su hermano mayor GPT-4o. La eficiencia de computación (y coste) se está normalizando en la IA generativa. OPENAI
Julián Estévez explica cómo los modelos fundacionales y el aprendizaje por imitación están revolucionando la robótica. La llegada de los robots humanoides se está acelerando. LINK
Andrew Ng, uno de mis investigadores IA de cabecera (y de la cabecera de millones de personas) está realmente inquieto con el impacto negativo que la ley IA que se está fraguando en California puede tener en el desarrollo de modelos open source. LINK
Me ha cautivado (¿embaucado?) el elevator pitch de Odissey, una IA dirigida a Hollywood: “Debemos exigir más a la IA. Un breve recorrido por la red revelará que estamos inundados de contenidos de baja calidad generados por IA. Granjas de contenidos, bots de spam e incluso empresas bienintencionadas utilizan la IA para generar texto e imágenes con el objetivo de gamificar algoritmos y captar tu atención. Si no se hace bien, la generación de vídeos con IA podría ir en la misma dirección, inundándonos de vídeos aleatorios sin chispa ni historia. Con el tiempo suficiente, quizá nos volvamos adictos a estos vídeos basura, olvidando cómo es la narración humana de alta calidad. Tal vez los humanos seamos relegados a espectadores de historias, no a narradores. En Odyssey rechazamos este futuro. Contar historias es demasiado importante para nuestra forma de vida, y los narradores profesionales han demostrado que tienen mucho que ofrecer. Lo mismo ocurre con la inteligencia artificial, si la construimos bien. En lugar de sustituir a los humanos por algoritmos que optimizan los clics, creemos que una nueva IA visual debería ponerse en manos de los narradores profesionales. Esta IA visual debería permitirles no sólo generar vídeos asombrosos, sino también dirigirlos con precisión y contar las historias épicas que tienen en la cabeza. ODISSEY
Upskilling con IA: cómo la IA mejorará tu trabajo. Un fascinante artículo de investigación que nos plantea Fernando de la Rosa para entender en qué ámbitos de nuestro trabajo nos puede ayudar más la IA, partiendo de su estructura de Soft Skills (útil en sí misma, por cierto). LINK
¿Cuán bueno realmente es ChatGPT programando? IEEE SPECTRUM
Estoy escuchando a mi DJ particular en Spotify (por IA). Ahora disponible en España (y en español). SPOTIFY
Y Meta a punto de liberar Llama-3 con 405 billones de parámetros. Un LLM multimodal y rendimiento cercano a GPT-4, pero … de código abierto. THE INFORMATION
Y Amazon anuncia Rufus (en USA), su asistente de compra. AMAZON

Buenísimo lo de que solo un 10% acepta el dato que contradice sus guts jaja
Me ha gustado mucho, y creo que no puedo estar más alineado con la visión que expones en este artículo. Sin datos, no hay ventaja competitiva. La IAG tiene un techo de valor, a no ser que la alimentes muy bien.
Hay algo que me gustaría revisar y es el impacto en la cadena de valor. Para mi hay dos circuitos. En el "circuito de la experiencia" viene un cambio enorme, ya que permite hacer simulaciones continuadas. Me has dejado pensando ;)